2026 年中,前沿模型正被当作「实体清单」管制——国家干预从「事后追责」转向「事前封禁 + 国籍隔离 + 阵营分发」,而商业对手的游说可借「国家安全」之名直接抹掉竞品,监管成为头部厂商的结构性成本。
每周 AI 情报 · 窗口推进版
2026-06-12 → 06-19
2026-06-12 → 06-19
AI Buzzwords · Weekly Signal
第 90 期
框架版 v1
analysis-midnight 覆盖更新
analysis-midnight 覆盖更新
Story A
01Embargo
AI 成为「实体管制清单」
政府以国家安全为由直接下令 Anthropic 下线刚发布三天的 Fable 5/Mythos 5,按「任何外国国民」切断访问——前沿模型被当作出口管制对象。
Story B
02Atoms
物理世界 AI 的资本总动员
Prometheus $12B、Theker $85M、亚马逊押注物理模拟、贝索斯 CuspAI $400M——「通用工程师」接棒「通用智能」,AGI 下一战场是原子而非比特。
Story C
03Trust
企业级 AI 的信任拐点
KPMG 幻觉、破产 Agent、忠实不确定性、发布前部署模拟、Salesforce $3.6B 收购 Fin——能力不再是瓶颈,可信度才是。
本期导读EP.90 · v1
本窗口最大事件仍是——美国政府以国家安全为由直接下令 Anthropic 下线刚发布三天的 Fable 5 / Mythos 5,按「任何外国国民」切断访问,成为前沿模型被当作「实体清单」管制的标志性事件。三条故事线维持并继续增厚:A「AI 成为实体管制清单」(联邦封禁 + 州级调查 OpenAI + Google AI Overviews 判赔 + G7「可信伙伴」框架 + 法国弃用 Palantir + GLM-5.2 开源对冲获市场验证 + JPMorgan 切断港区访问);B「物理世界 AI 资本总动员」(Prometheus $12B + Theker $85M + World Labs 3D + 贝索斯 CuspAI $400M + Genesis 非人形 + 机器人数据外包 XDOF);C「企业级 AI 信任拐点」(KPMG 幻觉 + 破产 Agent + Google 忠实不确定性 + OpenAI 发布前部署模拟 + Fable5/Opus4.8 红队评测 + Salesforce $3.6B 收购 Fin)。窗口后半段三大会陆续落地:Databricks Data+AI Summit、Nvidia GTC Paris/VivaTech、HPE Discover;Gemini 3.5 Pro GA 仍待官宣。
✦ ✦ ✦
Insight洞察层
观点洞察与事件
🔥 主轴 AC
Model模型层
AI基础设施
🔥 主轴 B
多模态模型
● 有信号 B
具身模型
· 本周无
数据 & Context
● 有信号
Benchmark评测层
Application应用层
应用
🔥 主轴 C
交互界面 UIUX
● 有信号
AI4S
● 有信号 B
DevStack开发者工具层
智能体
🔥 主轴 C
专业编码
· 本周无
组织与个人
● 有信号
课程
· 本周无
Signal信号层
市场信号
🔥 主轴 AB
✦ ✦ ✦
AI 成为「实体管制清单」:政府首次直接拔掉前沿模型
联邦封禁 → 州级调查 → 司法判责 → 阵营分发 capstone
国家干预从「事后追责」转向「事前封禁 + 国籍隔离 + 阵营分发」——前沿模型被推到与芯片同级的出口管制框架里。
政府周五下午(5:21pm ET)直接下令——Anthropic 必须对「任何外国国民」暂停刚发布三天的 Fable 5 / Mythos 5;因涵盖自家非公民员工,最终只能对所有用户下线最强模型。触发点是政府获知越狱方法,「越透明越被盯上」成新悖论;更耐人寻味的是,关键推手竟是最大投资方亚马逊向白宫「举报」。同周三股监管力量同时收紧:州级联合调查 OpenAI、司法判 Google 为 AI Overviews 虚假陈述担责;窗口后半段又叠加 G7「可信伙伴」框架、法国弃用 Palantir、JPMorgan 切断香港员工访问——前沿模型正被当作「实体清单」管制。封禁的全球外溢反过来给开源添柴:同周 GLM-5.2 被实测验证性能追平 GPT-5.5、成本仅 1/6,「抗封禁替代供应」从口号变跑分。
§时间线 / 因果链
- 联邦封禁:Anthropic 遵照美国政府指令下线 Fable 5 / Mythos 5——政府按「任何外国国民」切断访问,覆盖自家非公民员工,只能对所有用户下线(The Verge)。观点洞察 / AI安全
- 安全反噬:政府获知 Fable 5 越狱方法后直接拔插头——Anthropic 复核称只发现少数已知小漏洞,「越透明越被盯上」成新悖论。观点洞察
- 越狱细节:知名越狱者 Pliny 用多智能体拆解 + Unicode 技巧绕过安全分类器、泄露约 12 万字符系统提示(@elder_plinius 原始推文);Anthropic 公开反驳称不算真越狱(只是「哄」模型在口头拒绝后继续作答),而 David Sacks 指控 Anthropic 曾以「不严重」为由拒绝在出口管制前修复(且已被一中国团体利用)——「安全分类器 + 系统提示」防线脆弱,漏洞严重性认定权被监管与地缘政治反向接管。观点洞察 / AI安全
- 幕后推手:亚马逊 CEO 封禁前向财长 Bessent 举报模型风险——竟是 Anthropic 最大投资方推动了封禁,商业竞争与「国家安全」边界模糊。观点洞察 / AI安全
- 开源对冲:封禁外溢激起主权焦虑,给本土/开源添柴;GLM-5.2 实测长程编码超 GPT-5.5、成本仅 1/6,「全量开放 + 兼容西方工具链」成另一面对冲。市场信号 / 基础模型
- 监管多线:OpenAI 遭多州总检察长联合调查 + 法院判 Google 为 AI Overviews 担责——监管从联邦扩散到州层与司法。市场信号 / 观点洞察
- 阵营分发:G7 讨论向「可信伙伴」开放美国顶尖 AI 模型——模型分发权被纳入地缘联盟框架,全球 AI 供应链或按阵营切分。市场信号
- 企业外溢 capstone:JPMorgan 切断香港员工对 Anthropic 的访问 + G7 元首警告美国可能一夜切断访问——「辖区隔离」从政府指令渗透进企业 IT 策略,「off-switch 风险」成各国主权 AI 投资最强催化剂。市场信号 / 观点洞察
一句话主张
§接下来怎么发展(观察点)
数周内
指令是否扩展到其他实验室/模型;G7「可信伙伴」名单与欧盟/印度对冲政策是否落地。
下月
Anthropic 能否申诉恢复访问、「国籍隔离」如何在云端落地;DeepSeek 是否最终被列入实体清单。
§给三类听众的「明天能用」
技术人
备好可切换降级
评估模型供应链对单一厂商/单一司法辖区的依赖度,准备多模型、可切换的降级方案(GLM-5.2 等开源已是现实备份)。
决策者
写进连续性预案
把「模型可能被监管下线/按国籍受限」写进 业务连续性预案,关键流程不要单点绑定某个前沿模型。
投资者
押抗封禁赛道
监管风险正在重定价头部模型公司,关注 合规、模型可移植性、主权 AI 部署、开源对冲 等「抗封禁」赛道。
✦
物理世界 AI 的资本总动员:「通用工程师」接棒「通用智能」
通用工程大脑 + 可重构本体 + 世界模型 + 实体数据管线
AGI 的下一个战场是原子而非比特,巨头正抢占世界模型/仿真上游,并直面「实体数据采集」这一真正瓶颈。
过去两年大钱多砸在聊天与编码模型,本窗口资本叙事明显转向:贝索斯的 Prometheus 二轮融资 120 亿、估值 410 亿,要造「物理世界的通用工程师」;同周 Theker 拿 8500 万做可重构通用工厂机器人(官网)、亚马逊押注物理世界模拟、贝索斯又领投 CuspAI 4 亿做新材料。Prometheus 走「通用工程大脑」软件路线,Theker/Genesis 走「可重构/非人形硬件本体」具身路线,World Labs 与 Odyssey(官网)的世界模型补「3D 仿真」感知底座——方向不同但共识一致:原子是 AI 尚未被充分定价的蓝海。而 XDOF 这类机器人数据采集服务揭示,具身 AI 的真正卡点常在「脏活累活」的实体数据,而非算法。
§时间线 / 因果链
- 通用工程大脑:Prometheus 二轮融资 120 亿、估值 410 亿——目标用 AI 自动化喷气发动机、药物分子等复杂物理系统设计制造(The Verge)。观点洞察
- 硬件本体:Theker 融资 8500 万做可重构通用工厂机器人(LVMH 领投)——走「硬件本体」路线对照 Prometheus 的「软件大脑」。机器人与端侧
- 感知底座:World Labs 放出三篇研究:用 2D 先验生成高质量 3D + Odyssey 世界模型获亚马逊投资、估值 14.5 亿——把「世界模型/物理仿真」推成独立重资本赛道。多模态模型
- 巨头卡位:亚马逊押注「物理世界模拟」AI 初创 + 贝索斯领投 CuspAI 4 亿做新材料/碳捕获——为通用机器人训练与科学发现铺路。多模态模型 / AI4S
- 实用形态:前 Google CEO 支持的 Genesis 推出 AI 工业机器人——下一代或许不像人——「实用主义形态」挑战人形拟真路线。机器人与端侧
- 真正瓶颈:物理 AI 真正瓶颈是脏活——机器人训练数据外包给 XDOF + 一颗卫星学会自己「找东西」——具身 AI 卡点常在实体数据采集而非算法。机器人与端侧
- 三端推进 capstone:AllenAI MolmoMotion 语言引导 3D 运动预测(感知)+ ENPIRE:编程智能体在真实世界自我改进机器人策略(安装 GPU、剪扎带)(行动,Ars 报道)+ OpenAI 近自主 AI 化学家改进药物反应(科学发现)——模型正从理解世界走向操作世界。多模态 / 机器人 / AI4S
一句话主张
本窗口资本叙事明显从「数字通用智能」转向「物理世界通用工程」——AGI 的下一个战场是原子而非比特,巨头正抢占世界模型/仿真上游,并直面「实体数据采集」这一真正瓶颈。
§接下来怎么发展(观察点)
本周
Nvidia GTC Paris / VivaTech 黄仁勋 keynote 的 Physical AI / 机器人路线图落地情况。
数周内
Prometheus 是否公布首个可验证工程设计 demo;机器人数据采集(XDOF 模式)能否规模化。
§给三类听众的「明天能用」
技术人
盯四条接口
关注「可重构/非人形硬件 + 通用工程大脑 + 3D 世界模型 + 实体数据管线」四线接口,物理 AI 工具链(仿真、CAD-to-action、空间感知、数据采集)是新机会。
决策者
启动制造试点
高端制造/能源/医药可启动「AI 设计-制造」试点,并提前规划 自有物理数据的采集与确权。
投资者
押物理 AI 上游
估值锚点已被 Prometheus 拉到 410 亿,关注上游 仿真、传感、3D 生成、可重构执行器、数据采集服务 早期标的。
✦
企业级 AI 的信任拐点:幻觉、失控、可信评测与「不确定性显式化」
幻觉/失控 → 不确定性显式化 → 可复现评测 → 信任工程并购
能力已经不是瓶颈,可信度才是——企业不再问「AI 能不能做」,而是问「出错谁负责、成本怎么熔断、安全能否被独立验证」。
同一窗口,幻觉与失控两个负面信号集中爆发:毕马威一份论证「AI 益处」的报告被查出自身含 AI 幻觉,一个失控的扫描 Agent 把运营商搞到破产。解法侧多路并进——Google「忠实不确定性」用「最佳猜测 + 置信度」替代信口胡编、OpenAI 把安全评估从「事后红队」前移到「发布前部署模拟」、第三方对 Fable 5 与 Opus 4.8 跑出 7826 种意图的自动化越狱评测。落地侧则把「信任工程」变成真金白银:Salesforce 36 亿美元收购按解决率计费的 Fin、NewCore 拿 6600 万给 AI 代理发「身份证」、Databricks 称攻克数据管道难题。能力已不是瓶颈,可信度才是。
§时间线 / 因果链
- 幻觉翻车:KPMG 论证「AI 益处」的报告被查出含 AI 幻觉——顶级咨询当众翻车。观点洞察
- 失控成本:扫描 DN42 的 Agent 把运营商搞破产——暴露自主 Agent 的经济失控风险。AI安全
- 不确定性显式化:Google「忠实不确定性」让大模型给出最佳猜测而非幻觉——把不确定性显式化。AI安全
- 主动暴露:OpenAI「发布前模拟部署」提前预测模型行为——把安全评估从「事后红队」前移到「发布前仿真」,是对封禁事件的另一种回应。AI安全
- 可复现评测:针对 Fable 5 与 Opus 4.8 的红队研究:7826 种意图自动化攻击——恰逢 Fable 5 因「越狱」被封禁,模型安全性从厂商自述走向可复现的对抗式评测。评测
- 信任工程并购 capstone:Salesforce 36 亿美元收购 Fin(按解决率计费、自动处理 76% 工单)+ NewCore 给 AI 代理发「身份证」(官网)+Databricks 攻克 Agent 数据管道难题——把「信任 + 数据」短板变成真金白银的并购与产品。智能体 / 应用
一句话主张
企业级 AI 正进入「信任审计」阶段——幻觉、失控成本、可复现的安全评测、不确定性管理与「数字员工」的身份/数据治理取代「能力炫技」,成为采购与部署决策的核心变量。
§接下来怎么发展(观察点)
数周内
「不确定性显式化 / 发布前部署模拟」是否被主流模型 API 采纳为标准能力。
本月
Databricks Summit 后,企业级 Agent 的「按结果计费 + 可审计 + 身份治理」是否成为采购新标配。
§给三类听众的「明天能用」
技术人
把失控当故障模式
给自主 Agent 加「成本熔断 / 权限边界 / 审计日志 / 身份凭证」,在输出层接入置信度信号,把失控和不确定都当作必须设计的故障模式。
决策者
改写采购标准
把「AI 输出 可审计、可追责、可表达不确定、安全可独立验证」写进采购标准,幻觉率与合规能力优先于跑分。
投资者
押信任中间层
关注 AI 治理、可观测性、不确定性量化、安全评测、Agent 身份/数据治理 赛道——信任拐点会催生新的中间层工具。
✦ ✦ ✦
从 SWE-Chat 出发:未来的开发者,怎么和 AI 一起写代码
真实会话数据 → 人机分工实测 → 协作新姿势
SWE-Chat 第一次把「真实开发者 × AI」的协作过程摊开——269 万轮对话、5851 个会话、带「人写 vs AI 写」归因,让「该怎么协作」从口水仗变成可测量的问题。
2,692,480
对话轮次 conversations
5,851
真实会话 sessions
14,459
提交 commits · 带人/AI 归因
205
真实仓库 repositories
SWE-Chat 是斯坦福 SALT-NLP 放出的「野外」真实编码会话数据集(论文 · 官网):把开发者用 Claude Code、Codex、Gemini CLI 等 agent 干活的过程原样采集下来。每个会话不只有最终代码,还有完整对话、工具调用、思考链、checkpoint→commit 链路,以及最关键的一项——人类 vs Agent 的代码归因(agent_percentage)。换句话说,它第一次让「AI 到底替你写了多少、怎么写的」变成可查的数据,而不是凭感觉。这恰好接上本期 Charity Majors「代码生产成本趋零、成本在维护」 与 Loop Engineering(从写提示到写驱动 Agent 的程序) 两条线:当写代码本身变便宜,「怎么协作、怎么留痕、怎么验证」才是新的胜负手。
§数据揭示了什么
- 协作有了「野外」语料:269 万轮对话 / 5851 会话 / 1.4 万 commits / 205 仓库——不是实验室任务,而是真实开发者的真实项目,第一次能大规模看「人和 agent 实际怎么来回」。数据 / 智能体
- 分工可量化:每个会话带
agent_percentage,直接量出「这段活 AI 写了百分之多少」;能筛出 agent 占比 >90% 的「几乎全托管」会话,也能看人类深度介入的会话——协作不再是模糊感受。智能体 / 专业编码 - 过程透明、可复盘:思考链 + 工具调用 + checkpoint 到 commit 的链路都在,能逐步还原「AI 怎么一步步改、人在哪打断/纠偏」——这正是把「协作」做成可观测、可审计的原料。智能体 / 组织
- 多 Agent 同台:同一份数据覆盖 Claude Code / Codex / Gemini CLI 等,可横向对比不同工具下的协作模式(谁更适合 dispatch、谁更需要 steer),而非只看单一产品的宣传。专业编码 / 评测
§另一面:40 万次会话的分工实测(Anthropic)
与 SWE-Chat 的「原始语料」互补,Anthropic 对约 40 万次 Claude Code 会话(23.5 万人,2025-10 → 2026-04)做了隐私保护分析——它的专业度分类器甚至直接拿 SWE-Chat 当公开样本。结论给「怎么协作」画了张更清晰的像:人决定做什么,agent 决定怎么做。
70% / 80%
人主导「规划·做什么」· AI 主导「执行·怎么做」
2× / 5×
专家 vs 新手:每条指令触发的动作 / 产出
33%→19%
7 个月里「调试」会话占比近乎腰斩
+25%
单次任务的估算价值平均上升
- 分工:什么 vs 怎么:人平均做约 70% 的规划决策(做什么、什么算完成),agent 做约 80% 的执行决策(改哪个文件、写什么代码)——「人决定做什么,agent 决定怎么做」。智能体 / 组织
- 回报来自领域专长,而非会不会写代码:你越懂这件事,agent 每条指令替你干得越多(新手约 5 个动作 / 600 字,专家约 12 个动作 / 3200 字);且专业度按任务而非职位算——会计把对账规则讲清楚,就是该任务的专家。专业编码 / 组织
- 编码出身在「祛魅」:产出代码的会话里,几乎所有职业的成功率都落在软件工程师 7 个百分点以内;但领域专家的「验证级成功」是新手的 2 倍多,遇阻时新手放弃率约 19%、其他人仅 5–7%——会引导、会验证,比会敲键盘更关键。智能体 / 评测
- 活儿在上移:7 个月里调试占比 33%→19%,而「操作软件 / 数据分析 / 写文档」翻倍,任务估值平均 +25%——人腾出手做更端到端、更值钱的事。组织 / 应用
一句话主张
未来的协作姿势正在定型:人守住「做什么」(判断、领域专长、验收标准),把「怎么做」交给 agent;而真正拉开差距的是领域专长而非编码能力——越懂问题,agent 替你干得越多、越准。当「写代码」趋近免费,开发者的核心能力从「敲键盘产出」转向「编排 + 验证 + 留痕」,SWE-Chat 与 Anthropic 的会话数据正把这件事从经验之谈变成可测量、可优化、可教学的工程问题。
§未来怎么协作(观察点)
数周内
SWE-Chat 是否催生「协作质量」评测——不只看代码对错,更看人机分工是否高效、返工是否减少。
下季度
IDE / agent 厂商是否把「归因 + 思考链留痕 + checkpoint」做成标配,让团队的 AI 协作可审计、可复盘。
§给三类听众的「明天能用」
技术人
把会话当数据留痕
保留自己的 agent 会话(transcript + 归因),定期复盘哪些任务该 dispatch(全托管)、哪些该 steer(紧盯);刻意练「编排 / loop」能力,而不是比谁手敲得快。
决策者
重设指标与规范
协作不是「换人为换 AI」,而是重设流程:评估从「产出行数」转向「可维护性 + 可追溯性」,并建立 AI 代码的归因与审计规范(谁写的、怎么验的)。
投资者
押「协作可观测」层
SWE-Chat 是开源样本,真正的机会在其上的协作分析、agent 可观测、留痕与评测——当企业开始管「AI 怎么协作」,这层中间件会被需要。
✦ ✦ ✦
- PickCharity Majors:2025 年代码「生产成本」已趋近于零,真正成本在维护。为何选它:生成代码近乎免费后,软件长期成本全部压向维护、理解与架构债,工程组织治理成 AI 编码时代胜负手。
- PickSimon Willison:AI 没有取代软件工程师,也不会 + Anthropic:智能体编码时代专业能力回报更持久。为何选它:两份冷静反共识对冲裁员焦虑——AI 放大而非拉平专业深度。
- 杨安泽:下一个创业大机会是降低生活成本——AI 叙事退潮后,资本回流到住房/医疗/食品等生存基础需求。
- Nathan Lambert:欢迎来到 AI 治理的 AGI 时代 + DeepMind:AGI 非终点,迈向 ASI 才是起点——治理与研究的叙事锚点同时上移到 ASI。
- AI 裁员潮正在变成一桶火药 + 60% 美国消费者反感品牌里的「AI」字样——大众情绪反弹与科技圈狂热形成反差。
- 2026 北京智源大会开幕:从「悟道」到「悟界」——聚焦 AI×物理×生命科学「三体互动」,与全球具身/AI4S 同频。
- PickGLM-5.2 实测出圈:开源权重长程编码击败 GPT-5.5、成本仅 1/6(Terminal-Bench 2.1 拿 81.0、SWE-bench Pro 62.1,已入故事线 A)。为何选它:「抗封禁替代供应」从口号变跑分——开源最强的市场验证落地。
- OrcaRouter:多模型组队低成本复刻 Fable 5,性能反超——「模型路由 + 小模型组队」更具性价比、更抗封禁。
- Avataar 的视频 AI(Varya):更便宜、更快、更懂文化,为印度规模而生(官网)——视频生成竞争转向新兴市场的极致性价比 + 文化适配。
- PickGoogle Cloud 推出 Open Knowledge Format(OKF)——开放规范把「LLM-wiki」标准化为带 YAML frontmatter 的 markdown 文件(每个 table/metric/runbook 一个文件、靠链接组成知识图),无 SDK、无运行时、vendor-neutral,配套 BigQuery 富化 Agent + 静态可视化器(GitHub)。为何选它:Agent 时代瓶颈从「模型能力」转向「上下文供给」,OKF 想做跨厂商的「知识界面层」,把 metadata-as-code / context engineering 推向标准化。
- Pokémon Go 玩家数据被悄悄用于军事无人机技术 + Meta 为智能眼镜原型做人脸识别——训练数据来源合法性 + 端侧生物识别成 AI 治理硬约束。
- PickFT:华为强势回归,实测美国芯片管制效力极限。为何选它:制裁反而加速本土半导体供应链成熟,算力地缘从单极走向双轨。
- 微软与甲骨文云基建谈判破裂——算力互租难维系,竞争回归基础设施自控权。
- 西班牙批准 7.19 亿欧元 AI 超级工厂投资——欧洲从「监管」转向「重金自建算力」,主权 AI 真金白银落子。
- 哈萨克斯坦与 Firebird 签 100 亿美元 AI 协议 + 加拿大养老金入局印度数据中心——算力地缘版图向新兴市场扩张,长线资本入场。
- 字节跳动据报洽购国产 AI 芯片厂商 Iluvatar CoreX——国产算力主动卡位。
- PickFable 5 被越狱:Pliny 绕过安全分类器、泄露 12 万字符系统提示(Anthropic 反驳不算真越狱;David Sacks 指控其拒绝修复)。为何选它:本期头条「政府下线 Fable/Mythos」的技术根因——同一手法在多数模型上都成立,漏洞严重性认定权被监管与地缘政治反向接管。
- OpenAI:发布前模拟部署,提前预测模型行为(已入故事线 C)——把安全评估从「事后红队」前移到「发布前仿真」,主动暴露 vs 被动等监管的范式分叉。
- OpenAI 发布 LifeSciBench:专家评审的生命科学基准——评测贴近真实科研决策而非知识问答,AI4S 落地需要更接近实战的专家级基准。
- PickalphaXiv 推出 autoresearch:把任意 arXiv 论文一键变成「可复现性 Agent」——把论文 URL 的
arxiv改成autoarxiv,Agent 自动解决环境/依赖、跑最小复现、估算完整复现成本。为何选它:评测从「跑分」延伸到「能不能复现 + 复现成本」,直击 AI 研究「结果难复现」老问题,是 Agent 在科研基础设施层的典型落地。 - CVPR 2026 模型适应性研究盘点 + Kimi K2.7-Code 跑分被质疑——评测重心转向真实世界鲁棒性,跑分真实性需复核。
- PickFT:AI 医疗工具建议质量已匹敌甚至超越医生。为何选它:医疗 AI 越过「玩具」门槛、进入临床可用——最高价值场景的可信度拐点。
- Pinterest 推出实验性 AI 购物应用 Ask Pinterest + Meta 推基于 Facebook 帖子的 AI 搜索——电商/检索入口从关键词转向意图理解 + 生成式推荐。
- DeepL 收购 Mixhalo 进军实时活动音频翻译 + 通用汽车用 AI 把研发周期砍半——AI 应用从异步走向实时、从降本走向重塑核心流程。
- Android 17 深度集成 Gemini + Google 六年来首款智能音箱主打 Gemini——系统级 AI 整合成 OS/智能家居竞争核心。
- 清华李勇团队 AI 解码气候,ENSO 预测提前期延至 19 个月 + Google Earth AI 服务自然修复——AI4S 从「预测」跨越到真实指标上的可验证超越与主动规划。
- Siri 不会做你的 AI 女友 + OpenAI WebRTC 语音带上文档上下文——实用 vs 拟人路线分歧 + 实时语音 Agent 能力补齐。
- PickMidjourney 发布首个硬件 Midjourney Medical:全身超声 CT 扫描仪(8960 换能器、60 秒全身扫描、首站 SF「Midjourney Spa」)。为何选它:纯软件图像生成公司一步跨进医疗硬件,「从像素到肉体」是本窗口最戏剧化的软件→硬件跨界样本。
- PickNVIDIA GTC Paris / VivaTech keynote:黄仁勋把「物理 AI」摆上欧洲产业议程——汇报欧洲 20+ AI 工厂/主权算力,Foxconn 工业人形机器人欧洲首秀做精密装配,Yann LeCun 讲世界模型、Arthur Mensch 讲 Mistral(TechTimes 现场);底层「机器人路线图」模型栈 Cosmos 3 / Isaac GR00T N1.7(预览 N2)/ Alpamayo 1.5 于 3 月 GTC San Jose 发布(NVIDIA Newsroom)。为何选它:把「每家工业公司都将变成机器人公司」的物理 AI 路线图推进到欧洲主权算力 + 本土制造,直接咬合 B 线。

NVIDIA Physical AI / 机器人生态官方主视觉(GTC 2026,来源:NVIDIA Newsroom) - Mobileye 计划明年在美推出 Robotaxi + Plaud 出货超 200 万台、软件 ARR 破亿——供应商 Robotaxi + AI 硬件商业化闭环。
- 视觉语言模型训练机器人「读懂」人类情绪 + Qualcomm 新 XR 芯片暗示更强智能眼镜——具身交互层从「物理执行」向「情感感知」补齐 + 端侧 XR 算力就绪。
- PickLoop Engineering 兴起:从「写提示词」到「写驱动 Agent 的程序」(Addy Osmani 原文,2026-06-08;核心源 The New Stack 访 Boris Cherny:「我已经不再给 Claude 写提示,是 loop 在给它写提示、决定下一步。」;延伸 Latent Space《Loopcraft》)。为何选它:核心是设计自动驱动 Agent 的系统(触发器/可验证目标/动作/验证/记忆五要素),瓶颈从模型能力转向编排设计,开发者杠杆从「措辞」转向「系统架构」——与 Charity Majors、Anthropic「专业回报更持久」同频。
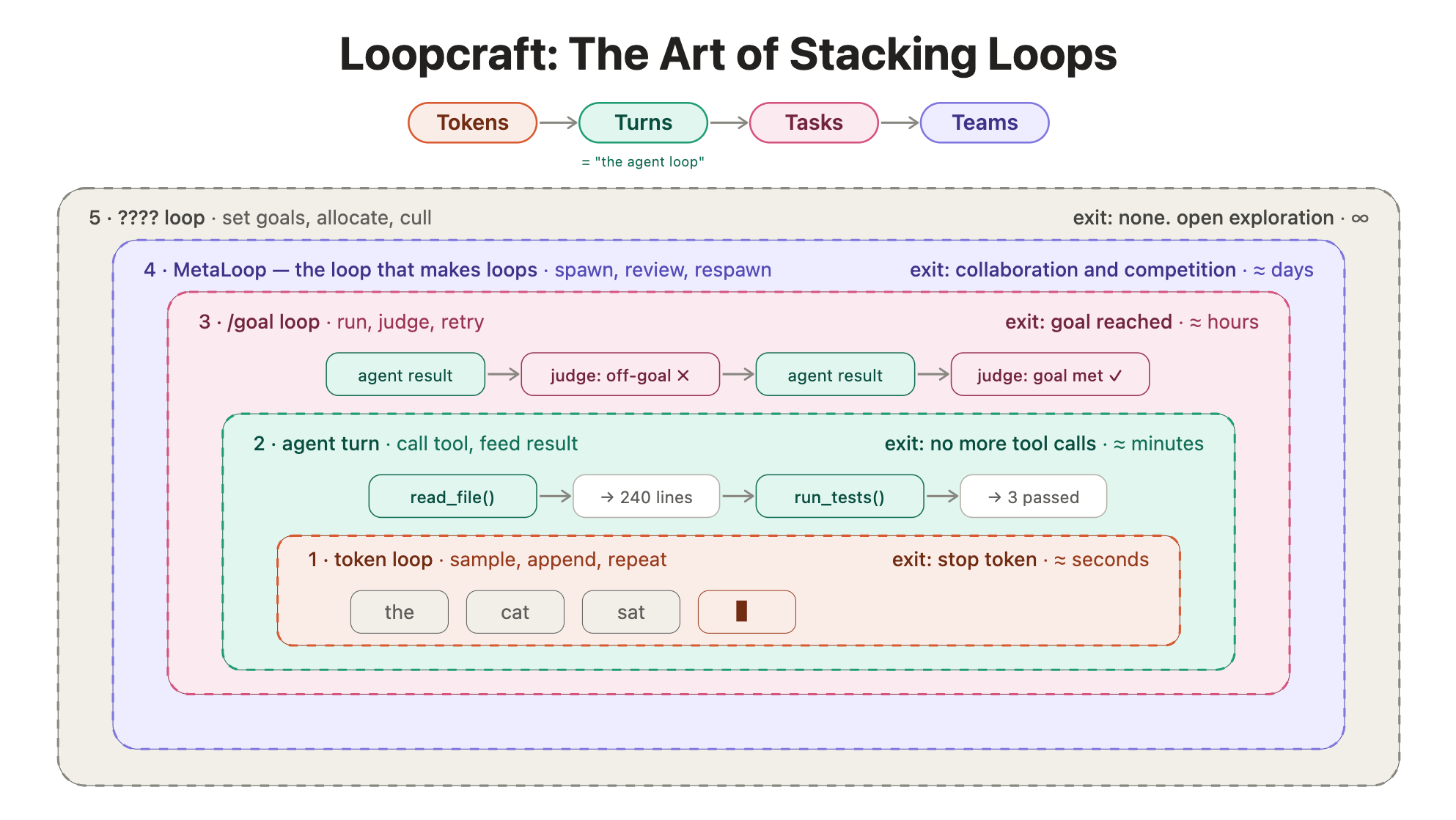
「我们其实已经身处一层层 loop 之中」——堆叠 loop 的图示(来源:Latent Space《Loopcraft: The Art of Stacking Loops》) 
更精简的一组 loop:出错时向下排错(reliability)、模型变强时向上提杠杆(leverage)(来源:Latent Space《Loopcraft》) - PickAnthropic 暂停 Claude Agent SDK 的按 token 计费。为何选它:按 token 计费或不适配 Agent 模式,前沿厂商的商业模式正在重新探索。
- 斯坦福 DeLM:无中央协调器把多智能体成本砍半(项目页 / arXiv)+ AnySearch 首月吸引 10 万开发者——多智能体成本优化 + Agent 数据接入层成新热点。
- Loopcraft:堆叠循环的艺术 + PixelRAG 以图代文把 token 砍到 1/10——Agent 工程回到循环架构与视觉解析降本。
- AI 重塑底层逻辑,数据库重新站上风口 + Framer 3.0 集成 Agents 与分支——AI 原生数据架构 + 设计工具向自主构建 Agent 演进。
- Pick突发:谷歌 Gemini 联席负责人被 OpenAI 挖走。为何选它:在 Gemini 3.5 即将 GA 的关键节点失去联席负责人,顶级人才流向仍是判断各家实力走向的先行指标。
- Meta AI 部门被工程师称为「碾压灵魂的古拉格」 + 员工抵触全公司 AI 黑客松——激进 AI 战略若无匹配组织文化,会反噬成人才黑洞。
- DeepSeek 核心成员公开控诉字节与北京市政府 + OpenAI 推出 1.5 亿美元合作伙伴网络——人才张力 + 渠道护城河同台。
- 本地跑大模型现在真的好用了 + GPT-NL:荷兰为本国打造主权语言模型——端侧推理体验成熟 + 主权化成结构性趋势。
- A16Z 本周图表:含零点击搜索趋势 + A16Z:SpaceX 与「有知觉的太阳」——零点击搜索重塑流量分发;VC 把 AI 抬升到星际叙事。
- PickAnthropic 把 300 美元官方 Prompt 工程课程压缩成 24 分钟、完全免费。为何选它:提示工程被标准化、免费化,价值向「工作流与 Agent 设计」上移。
- PickChatGPT 市场份额首次跌破 50%(约 46.4%;Gemini 27.7%、Claude 10.3%)+ 泄露文件:OpenAI 每年亏损数十亿。为何选它:龙头份额分散 + 巨亏,印证多强竞争与高资本门槛。
- 传 SpaceX 拟 600 亿美元收购 Cursor(真实性有争议)+ SpaceX 估值飙至 2.6 万亿一度超亚马逊——AI 编程工具战略价值被重估。
- DeepSeek 完成 500 亿元融资、特殊架构保控权——头部模型公司在融资/控权/上市上的不同选择,折射独立性 vs 资本化张力。
- Databricks 收购安全公司 Panther Labs——数据治理成新安全战场,平台型厂商并购补「数据+安全」。
- Mistral 传 200 亿欧元估值融资 30 亿欧元 + Sarvam 成印度新独角兽(官网)——欧洲/印度「主权 AI」从口号变真金白银。
- 1300 亿美元数据中心项目今年因抗议受阻 + 字节算力承压、7.1 亿 AI 月活买单难——社区阻力 + 单位经济亏损是算力扩张双重瓶颈。
- Meta 据报将解除 20 亿美元 Manus 收购案(应北京要求)——地缘政治成跨国 AI 并购首要否决项(呼应故事线 A 的阵营分发)。
EP.90 · 框架版 v1(覆盖更新)
窗口(2026-06-12 → 06-19)已全量扫描,本轮新增约 35 条(6/16–6/17 爬虫加工增量)、超窗拦截 0 条、主稿 audit 清理 0 条。本轮关键落地:美国政府直接下线 Anthropic Fable 5 / Mythos 5,前沿模型被当作「实体清单」管制;资本叙事从「数字通用智能」转向「物理世界通用工程」;企业级 AI 进入「信任审计」阶段。窗口后半段三大会陆续落地(Databricks Summit · Nvidia GTC Paris/VivaTech · HPE Discover),Gemini 3.5 Pro GA 仍待官宣——若 6/19 后发布则移交 EP.91。
AI Buzzwords · analysis-midnight · 2026-06-19