01
GLM 5.1 Thinking
z-ai
「✨ 它做了一件别人都没想到的事:换了个视角。」
Chat 28/35
API 26/35
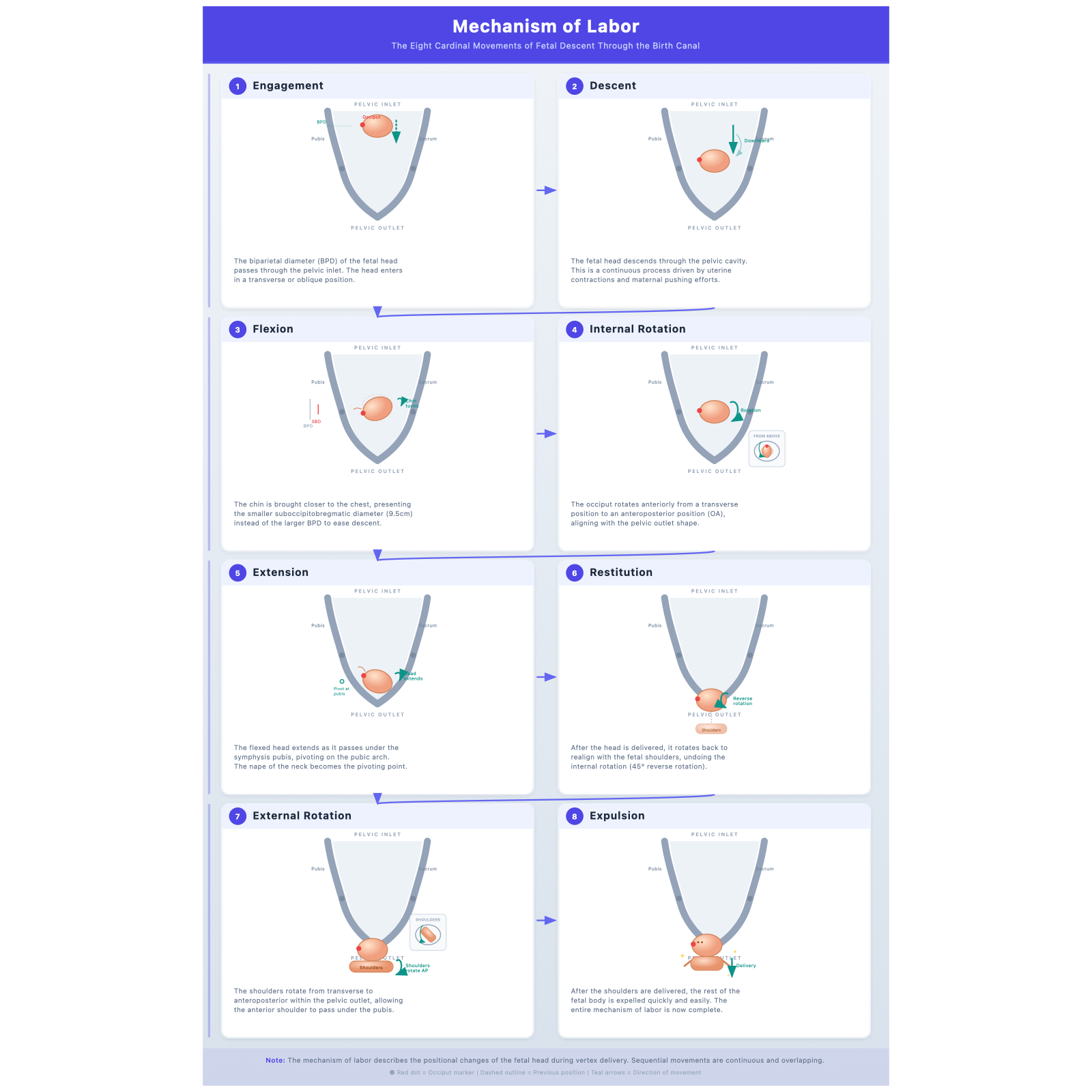
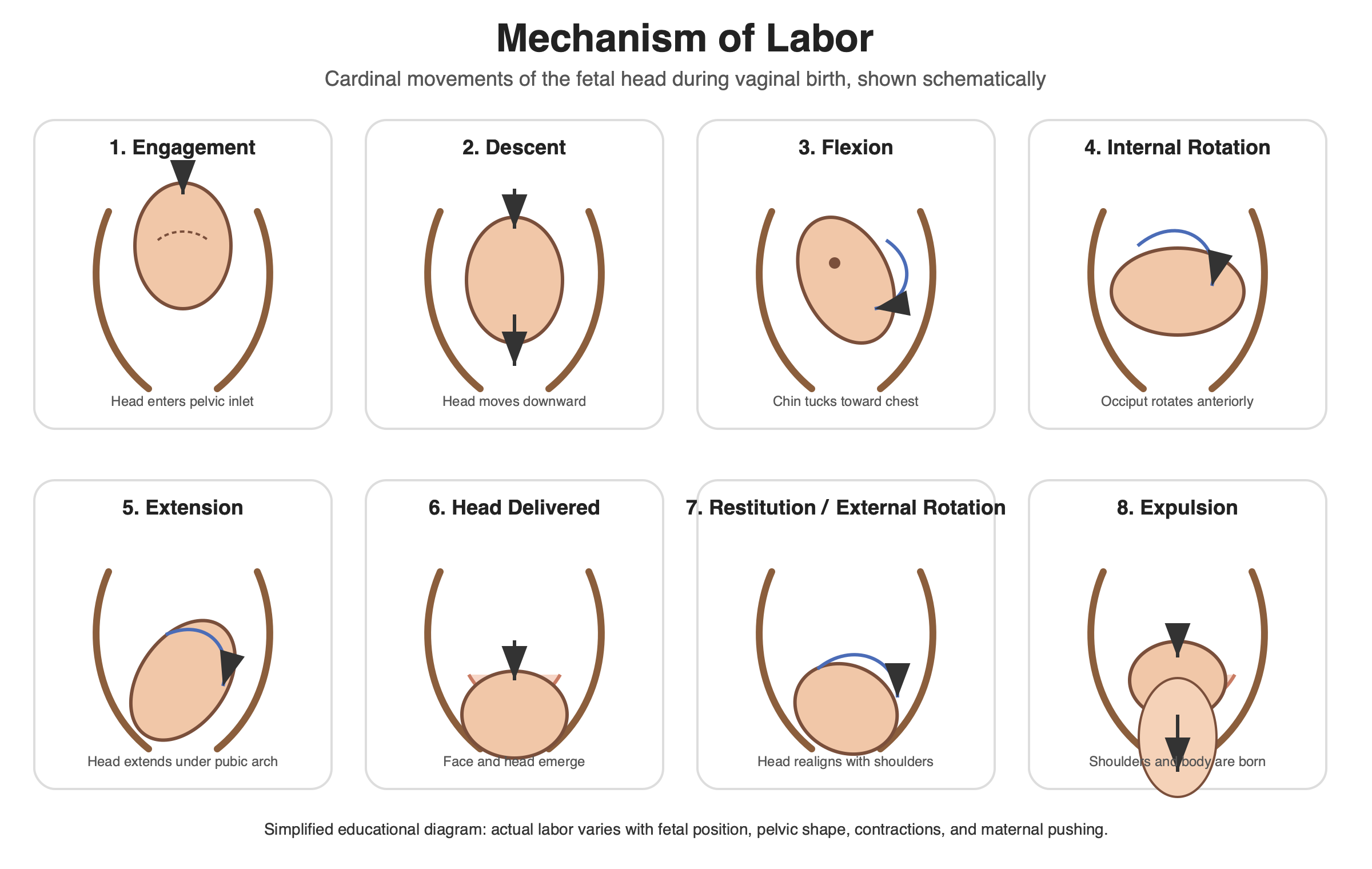
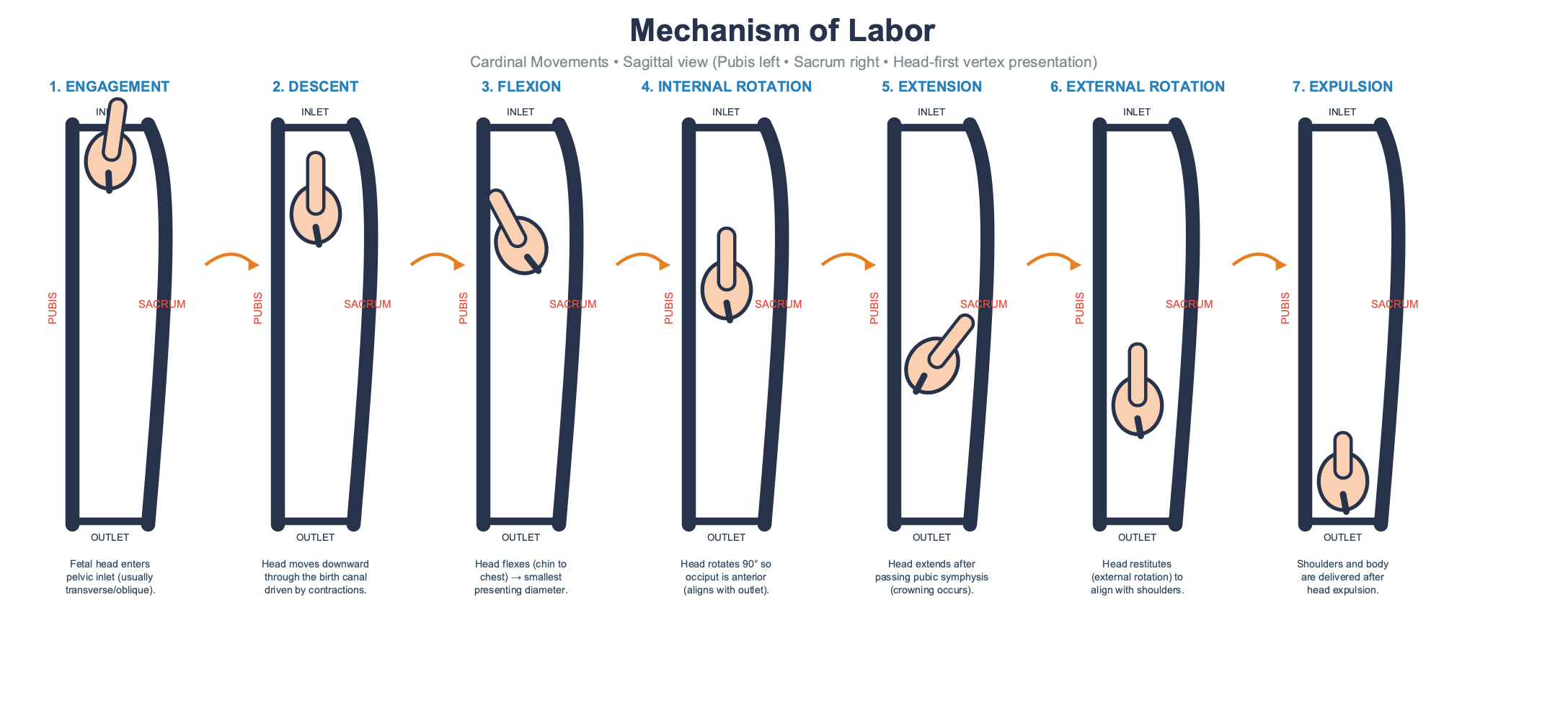
Chat 版和 API 版都在内旋转面板里加了俯视图——一个从骨盆开口向下看的视角,显示胎头从斜径转向前后径的过程。这是
Chat 版 8 个面板,大量青绿色箭头,步骤覆盖最完整(
起因是我老婆生孩子那天。8 个顶级模型,一个不可能的医学绘图任务,五个让人意外的发现。
周二,我老婆生了孩子。顺产。
原本的计划是:
💡 查着查着,我发现这件事根本不是我以为的样子。分娩不是「用力推」就结束的。胎儿在通过产道的过程中,要经历七个
这整个过程,
😤 我突然想把这个过程画出来。动画也好,示意图也好——让人能直观地看到胎头在骨盆里旋转的每一步。
然后我开始试。用 SVG 画——太难。改用
🤖 于是我把这个任务交给了 LLM。
Simon Willison 每次遇到新模型,就让它画一只骑自行车的鹈鹕。这个测试的妙处在于三件事同时成立:LLM 本来不该能画图;SVG 是代码,所以它们可以尝试;而鹈鹕骑自行车根本不可能发生——不存在「标准答案」,你只能判断模型是在理解还是在瞎编。
「这是一个不合理的困难测试……试着自己画一辆自行车,不看参考图。大多数人都会发现,他们很难记住车架的确切结构。鹈鹕也很难画,更重要的是——鹈鹕根本不能骑自行车,它们的体型完全不对!」— Simon Willison,AI Engineer World's Fair 主题演讲,2025
✨ 胎儿分娩机转(Cardinal Movements of Labor)满足同样的三个条件——而且难度比鹈鹕高出不止一个量级。
LLM 不该能画医学插图。SVG 是代码,所以它们可以尝试。而
最关键的是:「
Prompt 只有一句话:
每个模型测两个版本。Chat 版(橙色):打开各家网页界面,直接提问,截图,将输出 SVG 代码用 macOS qlmanage -t -s 1600 渲染为 1600px PNG。API 版(青色):通过 OpenRouter 直调,统一上面这一句 Prompt,同样方法渲染。
评分由 GPT-5.5(多模态视觉分析)完成,对每张渲染 PNG 盲评 7 个维度:
| 代号 | 维度 | 评分说明 |
|---|---|---|
| C1 | 步骤完整性 | 覆盖 7 个分娩机转步骤的比例:衔接→下降→俯屈→内旋转→仰伸→外旋转→娩出 |
| C2 | 解剖结构准确性 | 骨盆、耻骨联合、骶骨、坐骨棘等可辨识程度;胎头解剖细节 |
| C3 | 胎儿方向 | 是否明确呈现头先露(vertex)、头朝骨盆出口方向 |
| C4 | 内旋转视觉呈现 | 内旋转步骤是否有清晰图形表达(旋转箭头、俯视图等) |
| C5 | 外旋转视觉呈现 | 外旋转/复位步骤是否有清晰图形表达 |
| C6 | 运动方向标注 | 是否用箭头等方式指示各步骤运动方向 |
| C7 | 整体视觉清晰度 | 布局、配色、标注是否易于理解 |
每项 1–5 分,满分 35 分。
被测模型 8 个:GLM 5.1 Thinking、Gemini 3 Pro、Claude 4.7 Opus、Kimi K2.6 Thinking、ChatGPT 5.5 Thinking、MiniMax MAX、Grok、Doubao。另有 Manus 1.6 MAX 参与测试但因输出形式不同未纳入评分。
■ 橙色为 Chat 版 · ■ 青色为 API 版 · 满分 35 分
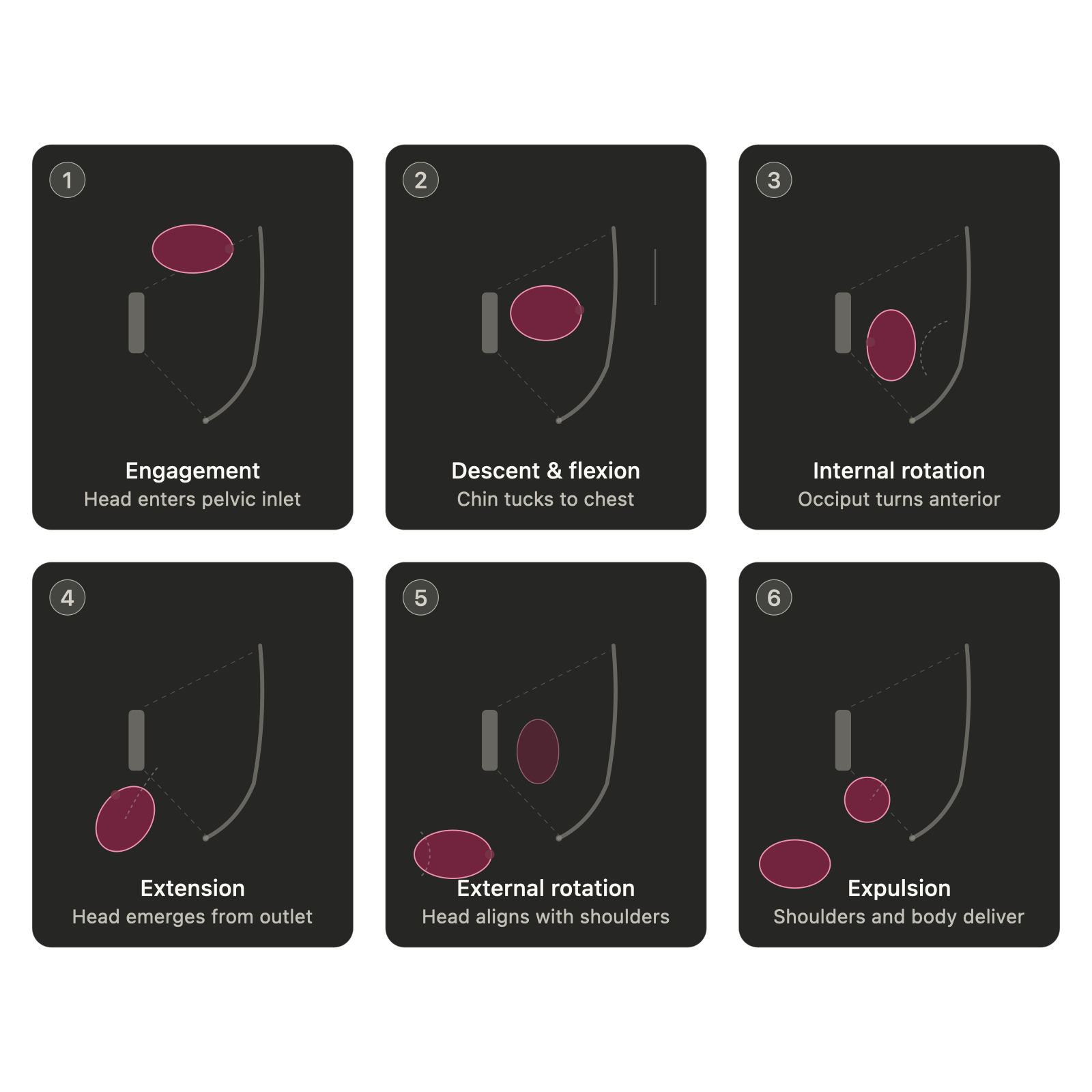
Chat 版和 API 版都在内旋转面板里加了俯视图——一个从骨盆开口向下看的视角,显示胎头从斜径转向前后径的过程。这是
Chat 版 8 个面板,大量青绿色箭头,步骤覆盖最完整(
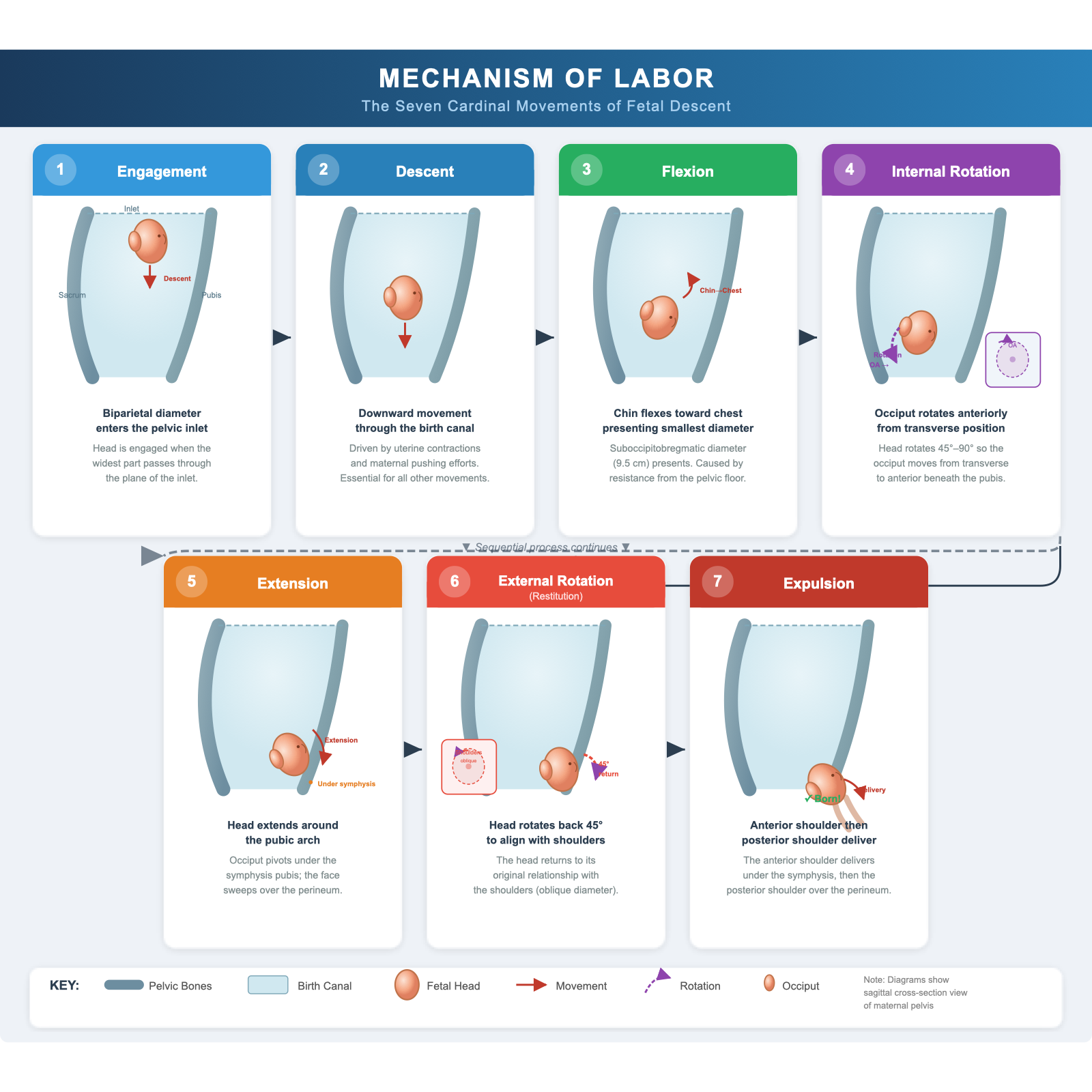
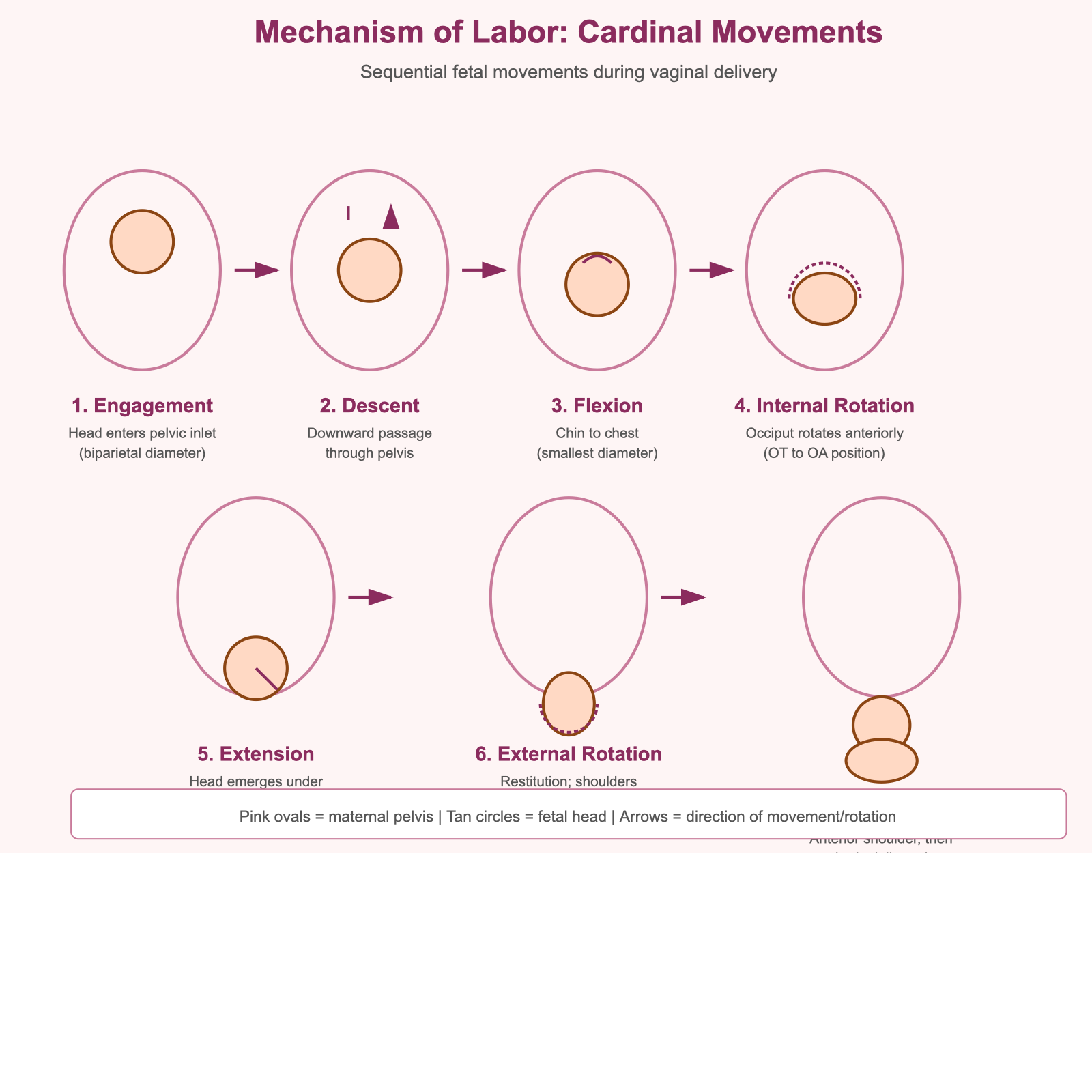
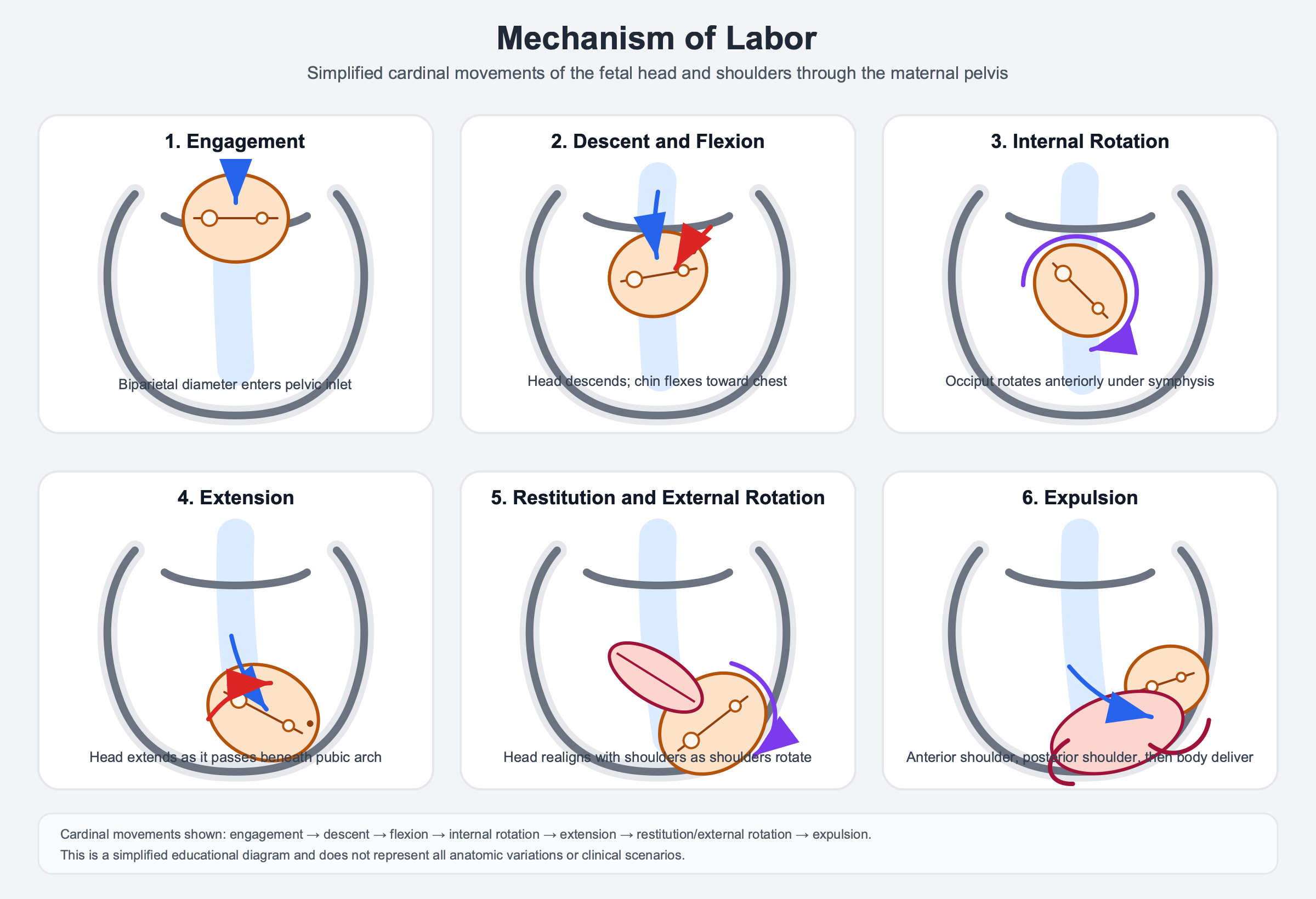
这是全批次最戏剧性的分裂。Chat 版产出的是一张完美的产品型时间轴信息图:7 步命名完整、布局整洁、字体清晰——但没有任何解剖图形或胎头绘制(
API 版则完全是另一件事:深色背景,
这说明相同的模型在不同界面下的「输出风格偏好」差异显著。Chat 界面可能有「产品化」的倾向——输出更像用户可以分享的卡片,而不是原始技术图形。
Chat 版 SVG 代码
「代码越多 ≠ 图越好」在这里得到了清晰的数据反证。API 版用了更少的代码,箭头(
<<svg(双尖括号),XML 不合法,浏览器解析失败。API 版缺少 xmlns 属性且 CSS class 未内嵌,渲染近乎空白。两版均得全维度 1 分(7/35)。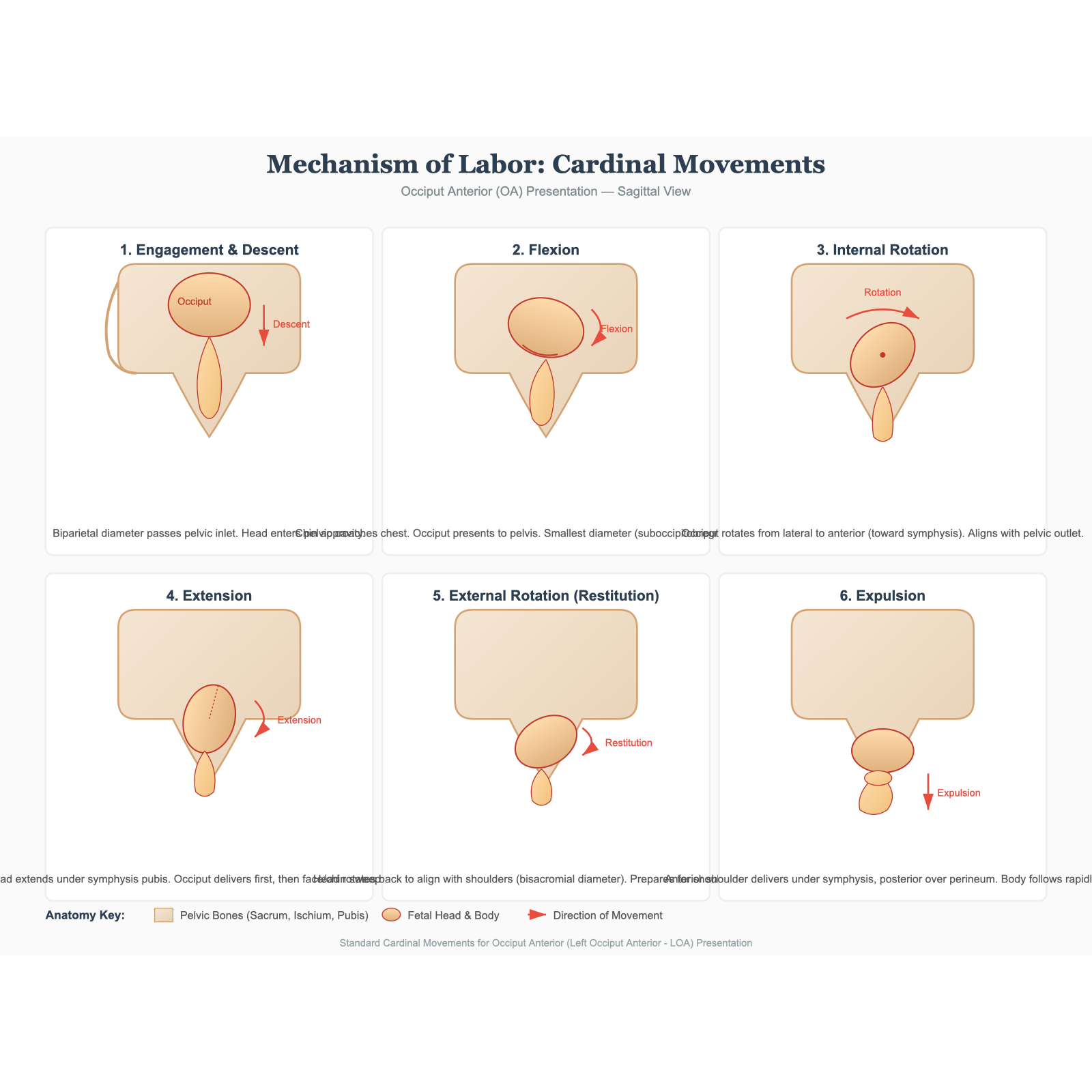
修复后的 Chat 版(仅移除一个多余的 <)得分
这是一个「模型会画,但代码有 bug」的典型案例。区分「SVG 语法能力」和「医学图示理解能力」很重要:原始分数
原始评分的 Chat 版(11/25*)和 API 版(21/35)都是基于截图不完整的图像:Chat SVG 是
Chat 版完整版:
📸 这也是这批测试里截图方法论影响最大的案例。Grok 两版同样受到截图截断影响(见下)。教训:用浏览器手动截图做 Benchmark,要确认 SVG 的完整宽度都在视口内。
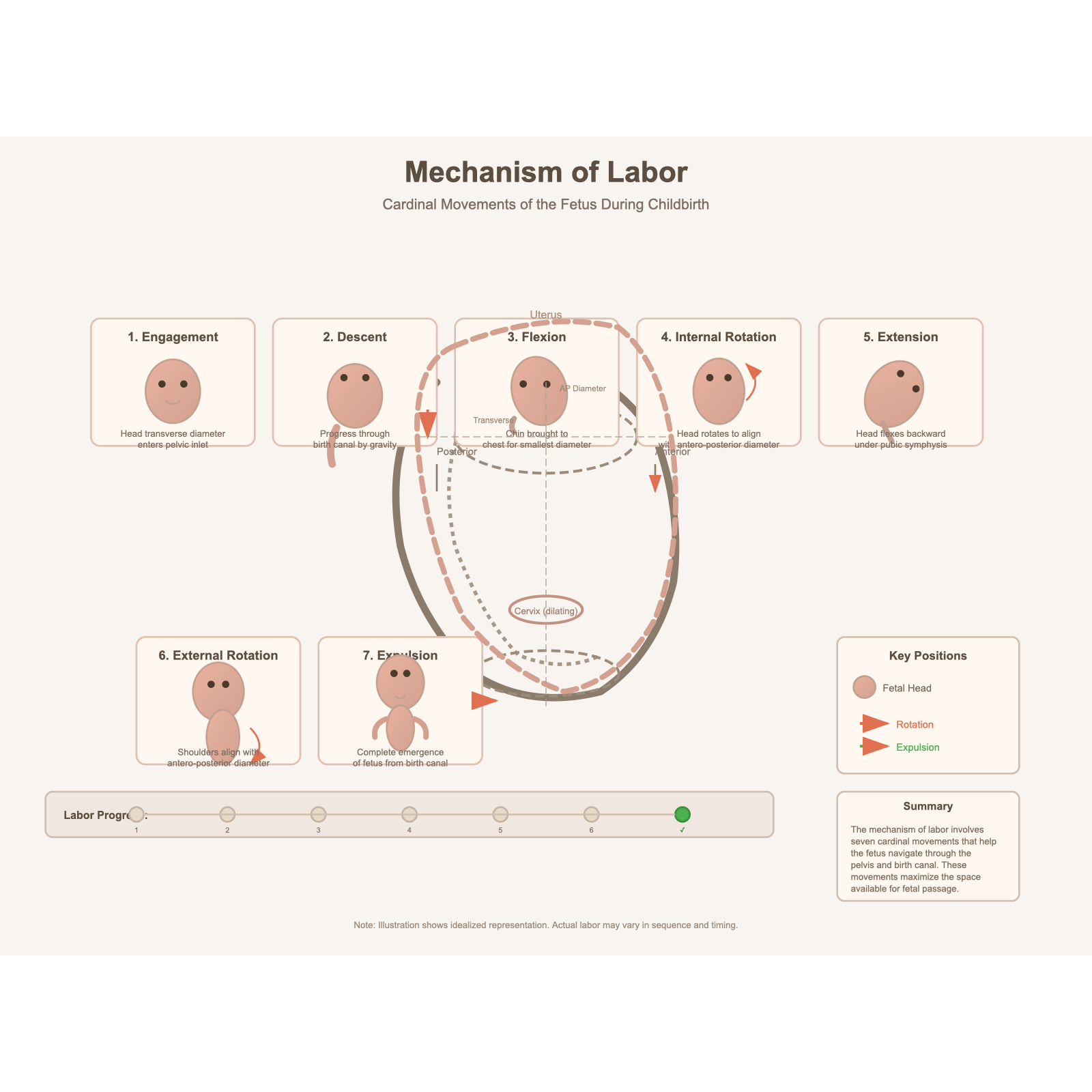
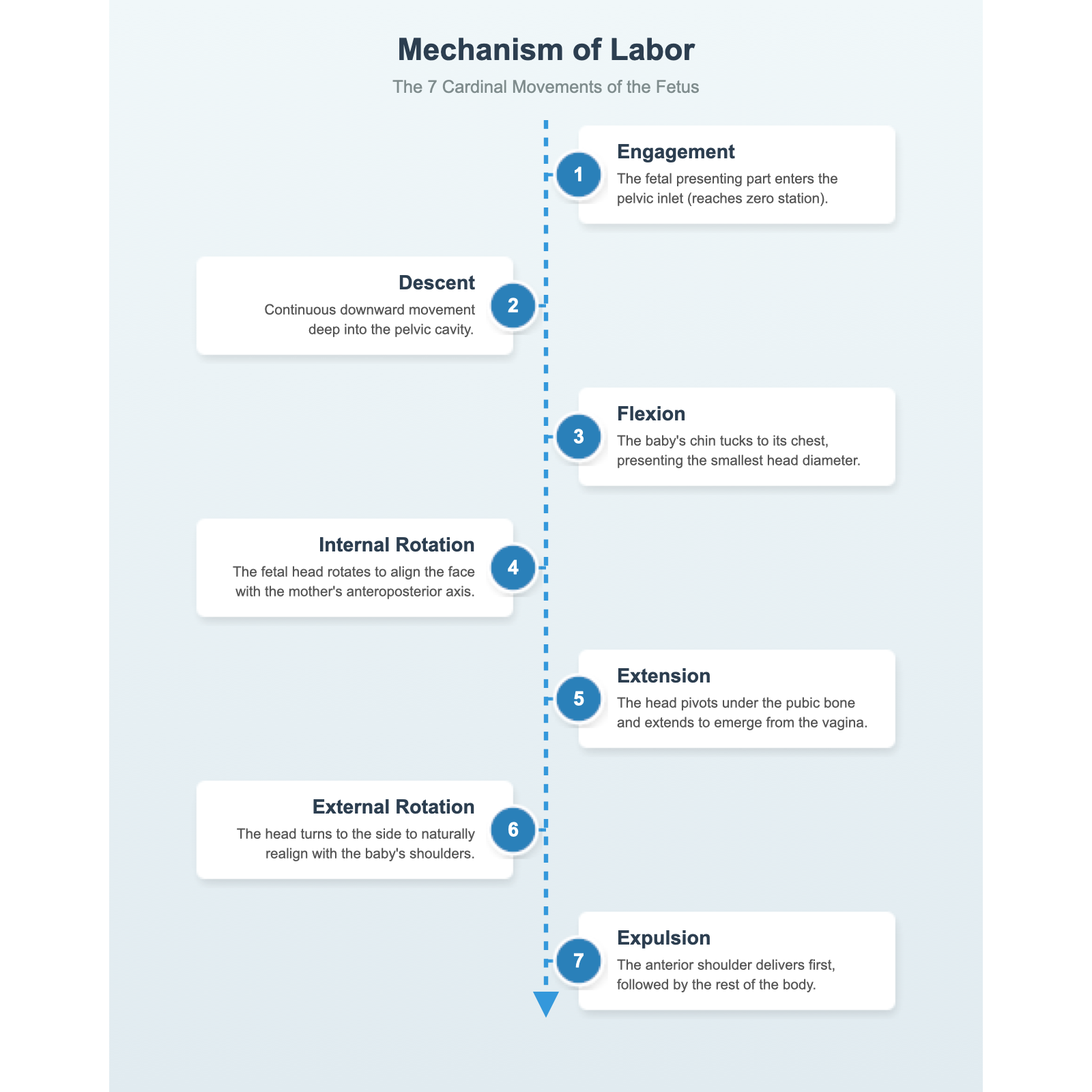
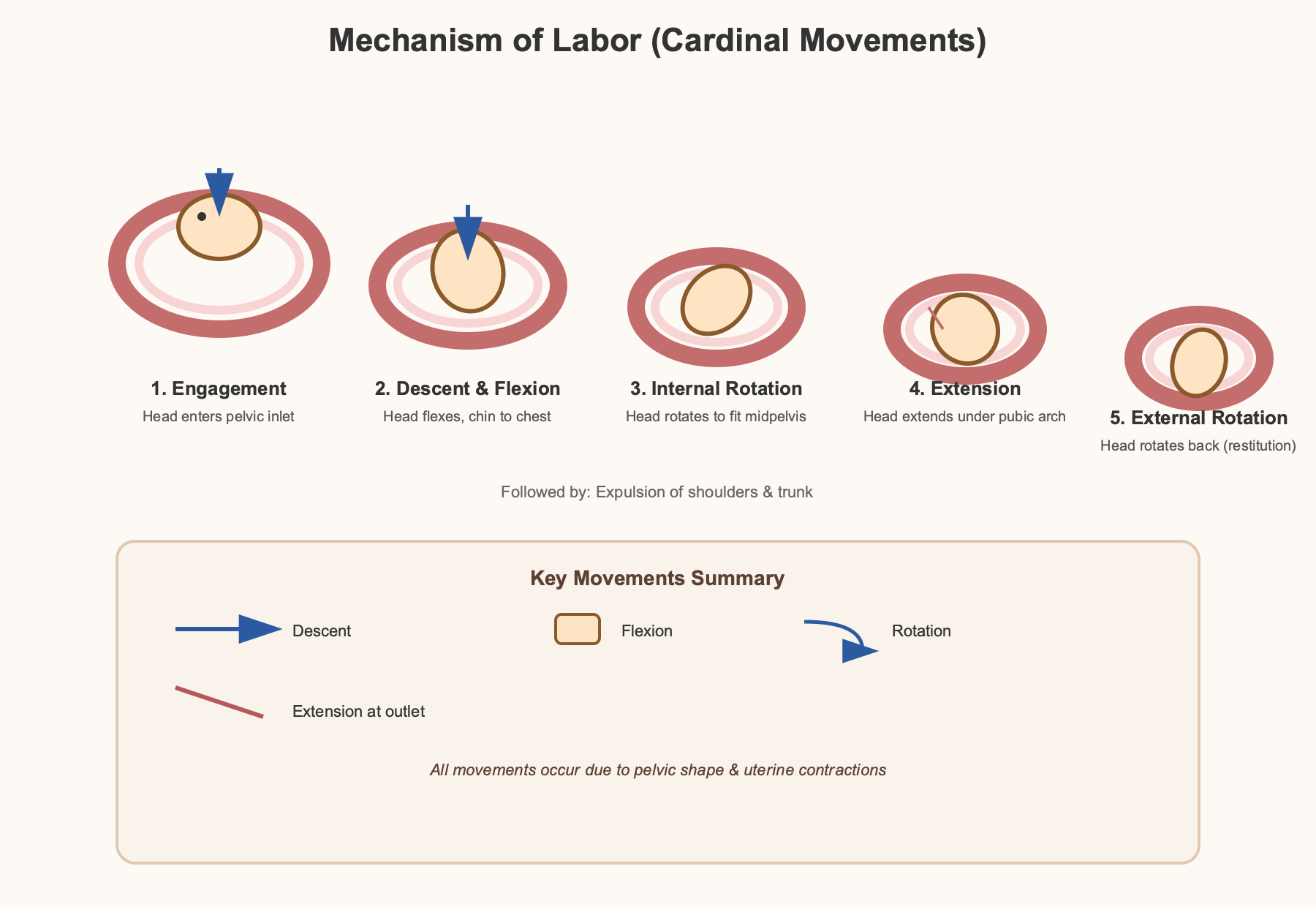
Chat 版是这批测试中视觉设计感较强的一张:带「Labor Progress」进度条,7 步命名完整(
API 版走向了另一个极端:
原始截图同样因为浏览器窗口宽度不足,裁掉了右侧内容(Chat 版 1450px 宽被截至约 870px;API 版 900px 宽步骤 5 被截断)。完整渲染后:Chat 版显示
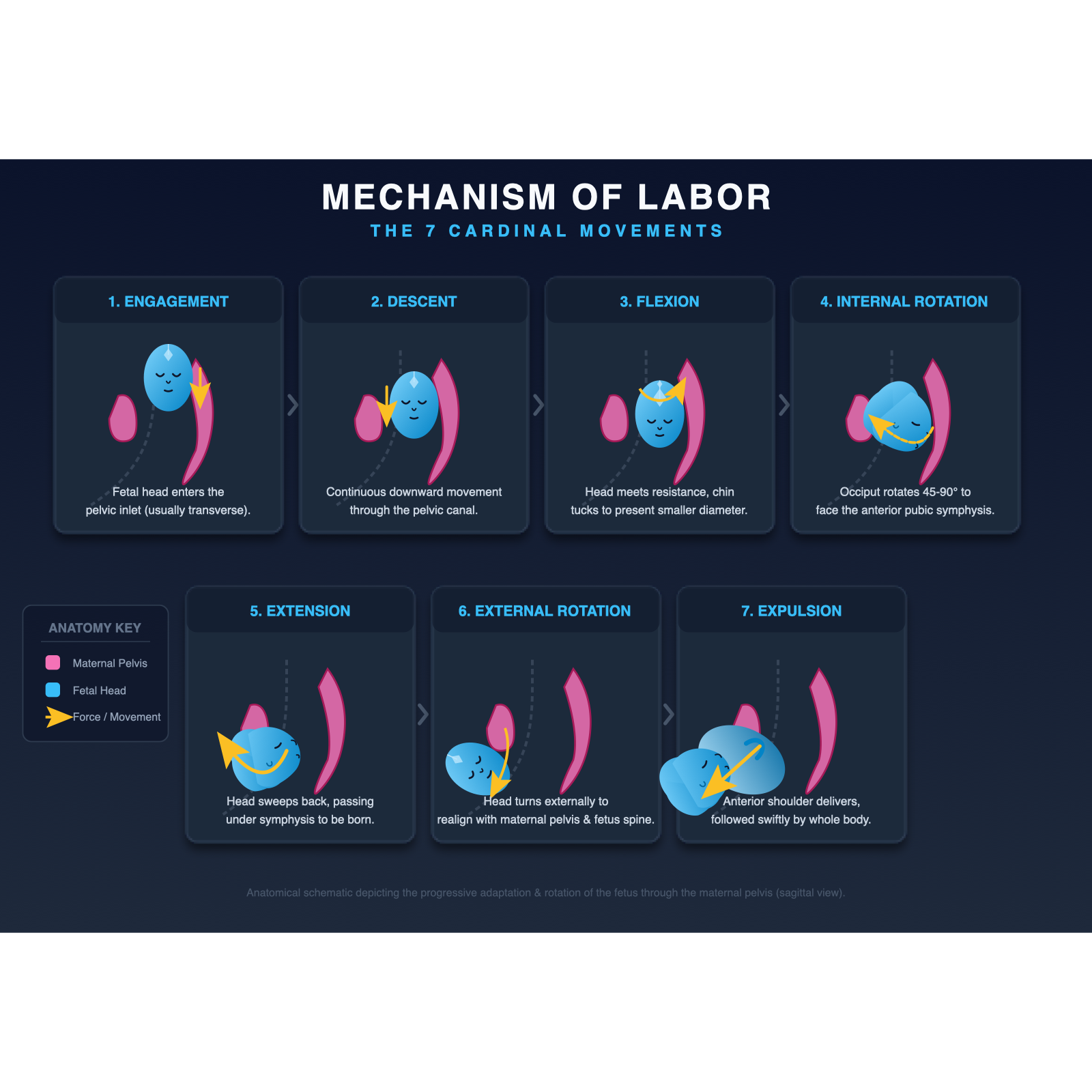
完整渲染后 Chat

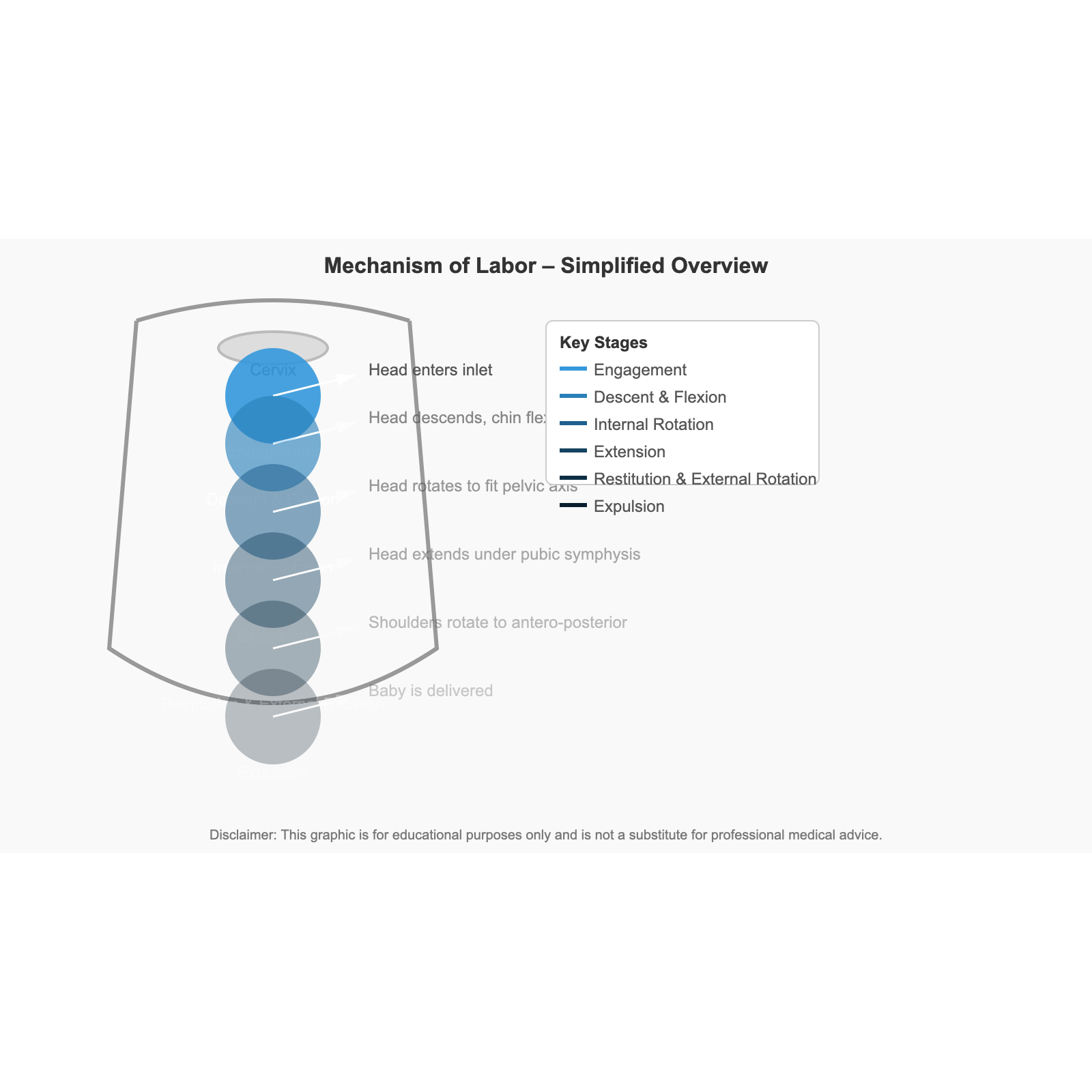
Chat 版含 XML 解析错误,浏览器渲染到第一个错误即停止,
整个 SVG 完全没有动态表达(
这不只是一次绘图竞赛的结果——这些模式揭示了当前 LLM 在「空间知识表达」上的系统性局限。
所有模型 C2(解剖准确性)均值约
内旋转是水平面上的旋转,矢状位侧视图表达不了它。全批次
Chat 版出了文字时间轴(
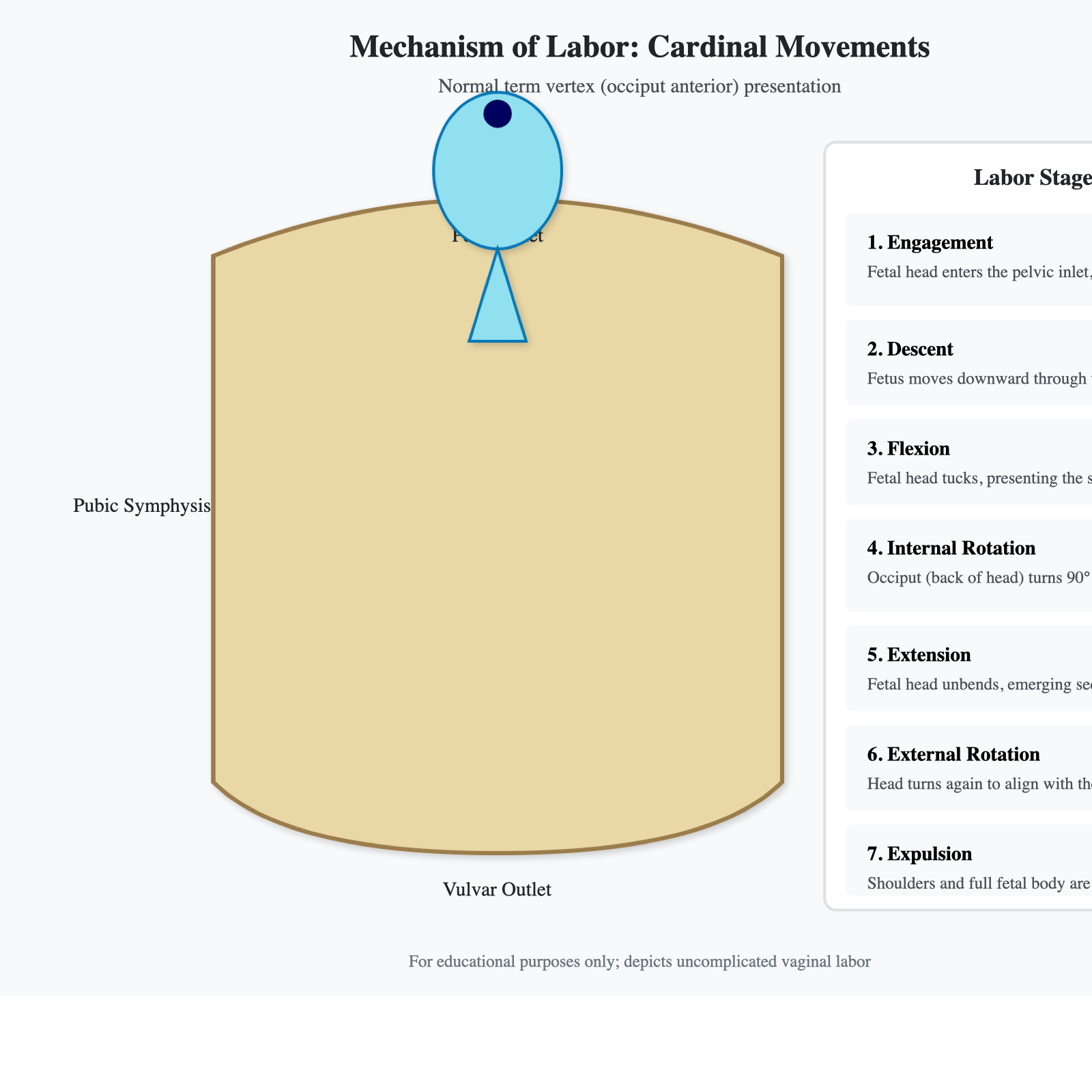
Claude Chat 版 SVG
这批测试里,
事后检查发现,
同一道题,同一套知识边界——换成视频会怎样?我用和 SVG 测试完全一致的 Prompt,分别在 Sora 2 和 Veo 3 上生成了分娩机转视频。
结论和 Simon Willison 关于鹈鹕的观察一致:
这个测试还会继续。Simon Willison 的鹈鹕基准已经运行了两年——最大的价值不是某一次测试的绝对分数,而是随着模型迭代的变化趋势。Gemini 2.5 Pro 的鹈鹕比 1.5 Pro 好了很多;o3 的鹈鹕比 GPT-4.5 好了更多。
分娩机转测试有类似的价值。今天因为 SVG 语法错误得 7 分的模型,三个月后可能得 21 分。今天解剖精度全批次均值
有一件事大概率不会因为数据量而改变:
我那个周一下午花了两个小时才大概搞清楚的事,模型
「每个人都需要自己的 Benchmark……我的鹈鹕测试开始时是一个笑话,但逐渐证明了它实际上有一点用。」— Simon Willison,《The last six months in LLMs》,AI Engineer World's Fair,2025
也许,那个 Benchmark,就是我们的梦想。✨
原始 SVG 文件、渲染 PNG、评分数据全部开放:github.com/fxp/mechanism-of-labor-bench · 可视化画廊:gallery.html